

Unlocking Scalable Data Pipelines with the Medallion Architecture Approach

In today’s data-driven world, the demand for efficient, scalable, and maintainable data pipelines is higher than ever. Organizations are constantly collecting data from a myriad of sources—web applications, IoT devices, transaction systems, and external APIs. However, raw data is rarely ready for immediate use. To derive meaningful insights and power data applications, this data must be cleaned, transformed, and enriched systematically.
This is where the Medallion Architecture—also known as the Lakehouse Architecture—comes in. It offers a structured, layered approach to organizing data in a data lake environment, enabling organizations to process large volumes of data effectively while maintaining data quality, consistency, and governance.
In this blog, we’ll explore what the Medallion Architecture is, how it works, and best practices for implementing it in your data platform.
What Is Medallion Architecture?
The Medallion Architecture is a data modeling and processing framework designed primarily for data lakes and lakehouse platforms such as Databricks, Delta Lake, and Apache Spark ecosystems. The architecture organizes data into three distinct layers:
- Bronze Layer: Raw or semi-structured data.
- Silver Layer: Cleaned and enriched data.
- Gold Layer: Aggregated, business-level data for reporting and analytics.
This tiered structure mirrors the process of data refinement—starting with raw, unprocessed inputs and transforming them into high-quality datasets optimized for analytics and decision-making.
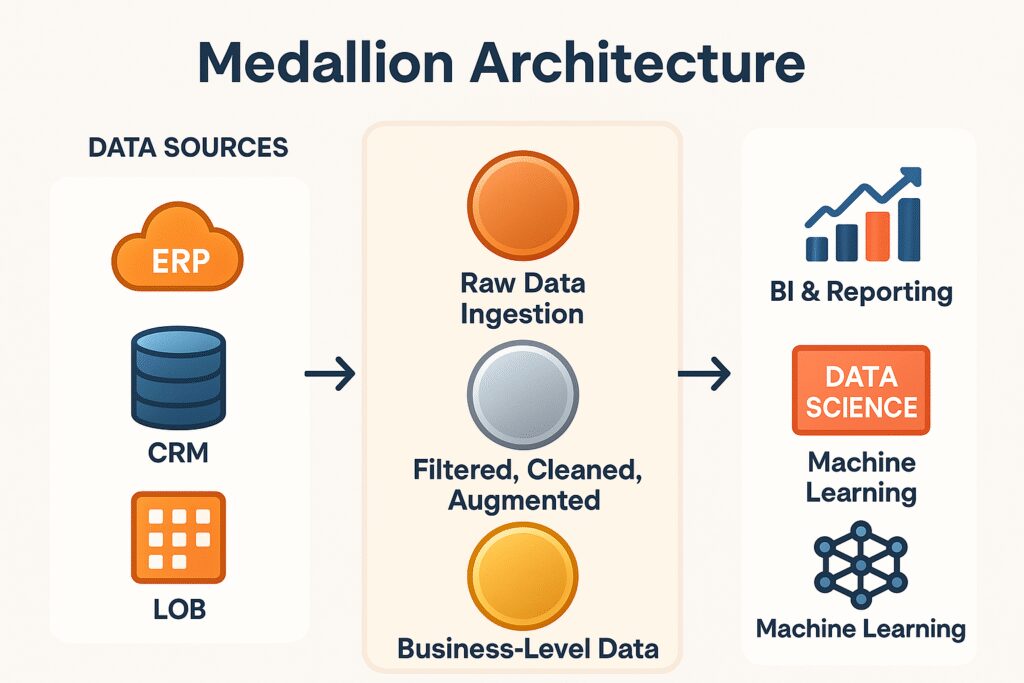
Figure 1: From Raw Data to Business Value: A Medallion Architecture
Why Use Medallion Architecture?
Data lakes are excellent for storing large volumes of structured and unstructured data at low cost. However, without structure, data lakes can become data swamps—repositories full of ungoverned, inconsistent, and low-quality data.
The Medallion Architecture addresses this issue by providing:
- Separation of concerns for different stages of data processing.
- Improved data governance and quality assurance.
- Scalability and performance through modular pipelines.
- Traceability and auditability for data lineage.
The Three Layers Explained
🥉 Bronze Layer – Raw Ingested Data
The Bronze layer is the foundation of the Medallion Architecture. It stores data in its rawest form, often directly ingested from source systems without any transformation.
Characteristics:
- Schema-on-read: Data may be unstructured or semi-structured.
- Immutable: Data should be treated as append-only to preserve lineage.
- Sources: APIs, logs, streaming data, sensor data, RDBMS dumps.
Goals:
- Capture every piece of raw data for future reprocessing.
- Enable time-travel and rollback if needed.
- Maintain auditability for compliance.
Example:
A company may ingest raw JSON logs from a web server into the bronze layer, without parsing or validating the contents.
🥈 Silver Layer – Cleaned & Enriched Data
The Silver layer contains curated datasets that have been cleaned, filtered, and transformed for consistency. This is where data engineers typically perform data quality checks, joins, standardizations, and enrichments.
Characteristics:
- Structured format (e.g., Parquet, ORC, Delta).
- Business logic applied (e.g., deduplication, normalization).
- Joins with reference datasets (e.g., country codes, customer master data).
Goals:
- Make data reliable and consistent for analysts and data scientists.
- Reduce complexity by resolving anomalies and schema variations.
- Provide an intermediate layer for reuse in multiple downstream processes.
Example:
Transforming the raw JSON logs from the bronze layer to structured data that includes only valid session events, with enriched geo-location fields and deduplicated session IDs.
🥇 Gold Layer – Aggregated Business-Level Data
The Gold layer is the final layer, designed for consumption by business stakeholders, analysts, and dashboards. It includes pre-aggregated or denormalized datasets for specific use cases like KPIs, financial reporting, or ML model input.
Characteristics:
- Denormalized, easy-to-query format.
- Optimized for performance and usability.
- Subject-specific (e.g., Sales Dashboard, Customer 360).
Goals:
- Drive business decision-making with reliable data.
- Support BI tools, SQL queries, and ML workflows.
- Serve as a single source of truth for analytics.
Example:
Creating a Gold layer dataset that aggregates sales by region, customer segment, and time period, ready for visualization in tools like Power BI or Tableau.
| Bronze Layer | Silver Layer | Gold Layer | |
|---|---|---|---|
| Purpose | Landing Zone for all data | Validate and refine the raw data | Enriched Layer(s) for specified for each business unit. |
| Data Type | Raw data from point-of-sale terminals, customer interactions, and supplier APIs | Cleaned POS data (combined and merging data) | Aggregated Sales Data to a particular granularity, such as hourly or monthly |
| Data Format | Structured, semi-structured and/or unstructured | Structured | Structured |
| Access | Developers | Developers | All business people |
| Task(s) | Incremental Data Refreshes, Pipelines, Data flows, Notebooks | Data Validation, Pipelines, Data flows, Notebooks | Pipelines. Data flows, Notebooks |
End-to-End Data Flow Example
Let’s walk through a typical scenario of a retail company using Medallion Architecture:
- Bronze Layer:
- Ingest raw data from point-of-sale terminals, customer interactions, and supplier APIs into Delta Lake.
- Store the data as-is with timestamps and source metadata.
- Silver Layer:
- Clean the POS data by removing invalid transactions and standardizing currency formats.
- Join customer interaction logs with CRM master data for enrichment.
- Store the structured and validated data in a query-friendly format.
- Gold Layer:
- Aggregate total sales per product, region, and day.
- Generate a customer churn prediction dataset using historical engagement and transaction data.
- Expose the data via a SQL endpoint or API for use in dashboards.
Benefits of Medallion Architecture
✅ Data Lineage & Auditability
Since each transformation is layered and versioned, it’s easier to trace how a data point evolved from raw to refined.
✅ Improved Collaboration
Different teams can work on different layers—data engineers on Bronze/Silver, analysts on Gold—without interfering with each other.
✅ Simplified Maintenance
Issues can be diagnosed at the appropriate layer. If a Gold report is inaccurate, you can inspect the silver layer for anomalies before digging into raw data.
✅ Scalable Processing
The modular design lends itself to distributed processing systems like Apache Spark and allows optimization at each layer.
✅ Reusability
Silver datasets can power multiple gold outputs, promoting consistency and reducing redundancy.
Best Practices for Implementing Medallion Architecture
- Use versioned storage formats like Delta Lake to enable time-travel, schema evolution, and efficient updates.
- Apply transformations incrementally, especially in Bronze and Silver layers, to avoid reprocessing entire datasets.
- Automate quality checks at the Silver layer (e.g., null checks, referential integrity, data types).
- Document data contracts between layers to clarify expectations (e.g., schema definitions, refresh cadence).
- Use orchestration tools like Apache Airflow, dbt, or Azure Data Factory to manage dependencies and schedule jobs.
- Monitor pipeline performance and maintain logging across all layers for traceability.
When to Use Medallion Architecture
This architecture is ideal for organizations working with:
- Streaming and batch data from diverse sources.
- Data lakehouses like Databricks or Snowflake with Delta/Parquet formats.
- Data platforms with teams dedicated to ingestion, transformation, and consumption.
- Complex transformations that benefit from decoupling and modular pipelines.
It may be overkill for small, ad-hoc ETL jobs or use cases with limited data transformation needs.
Final Thoughts
The Medallion Architecture offers a modern, scalable solution for managing data pipelines in the era of big data. By separating raw, cleaned, and consumable data into distinct layers, it brings clarity, quality, and performance to your data platform.
As data becomes more central to every business process, using structured approaches like the Medallion Architecture will be key to building resilient, trustworthy, and efficient analytics systems. Whether you’re just starting to build your data lakehouse or looking to improve your existing pipelines, this architecture can serve as a blueprint for success.
Ready to elevate your data strategy? Contact our expert IT team today to discuss implementing the Medallion Architecture for your organization. Let’s start small and scale your data maturity together! Reach out now to learn more.
{kind=link}