

Data Warehouse
A Data Warehouse (DW) is a hub where data are collected and processed with a primary aim to provide business insights to the organizational users to make data-driven decisions on the go. The data warehouse is usually a centralized repository where different data sources (transactional systems, relational database management systems and others) are connected. This electronic storage can hold massive datasets which can be transformed into insights when they are manipulated by business analysts, data scientists and data engineers. The data warehouse is an integral part of any business intelligence solution especially when there is a need to serve a large enterprise. Unlike other relational database management systems, the data warehouse is built using the On-Line Analytical Processing Approach, which entails designing and developing analytical queries from large blocks of data. This approach is very effective for data mining, sales analysis, price forecasting, market research, and budgeting. Data modification (update, delete and insert events) can be executed easily. Query failure doesn’t affect the organizational activity on the front end however it can interrupt or delay the business intelligence insights’ accuracy
In this section, we will discuss how we usually set up a data warehouse and the various schemas we can use within a data warehouse. Every data warehouse usually contains multiple data tables. These tables hold data in columns (series of data placed in a table vertically which usually hold defined attributes) and rows (series of data placed in the table horizontally which hold values of each corresponding attribute) as shown in figure 1. There are two main data tables in the data warehouse setup. They are dimension and fact tables.
The fact table is the primary table in a dimensional model where the numerical performance measurements, metrics and facts of the business activity are stored. A fact table has two types of columns: those containing measurements and those that is a foreign key to dimension tables. The fact table usually sits in the centre of most data schema arrangements. The primary key of a fact table is a composite key that is made up of all foreign keys of the dimension tables connected to it.
A dimension table is a key associated with a fact table. The dimension tables contain the textual descriptors of the business. It simply holds the dimensions (who, when, what, why) of the fact table (metrics, measurement). A dimension usually has many columns: the column that holds the key and others which accounts for the rows in the dimension table. Dimension tables are the entry points into the fact table.

Figure 1: A table representation that shows the rows and columns combination
When designing a data warehouse, there are two schemas (data representation) we can use. We will discuss them and see their gains and drawbacks.
Star Schema
In a data warehouse setup, a star schema is implemented when the fact table is placed in the centre of many associated dimension tables. Although it is seen as the simplest type of data warehouse schema, it is one most data engineers adopt for these designs since it supports data summarization, filtering and grouping. The relationship between the fact table and dimension table can be one-to-one, one-to-many, many-to-one or many-to-many. In a star schema, the relationship is one-to-many where one is on the dimension table while many are on the fact table. This makes data filtering and grouping very efficient and seamless.
Snowflake Schema
The snowflake schema is another set-up used in a data warehouse. This technique contains a fact table that is positioned in the middle of all the dimension tables (just like the star schema) however these dimension tables are connected to other tables usually called sub-dimension tables. The introduction of these sub-dimension tables is due to the elaborate expansion and normalization of the dimension table. While the relationships between the fact=table and dimension tables look like those we can achieve in the star schema, the relationship between the dimension tables and sub-dimension tables are “one-to-one/many”. This means the dimension keys must hold a primary key (for the fact table) and foreign key(s) (for the sub-dimension table(s)).
Using the sample dataset: UK Bank Customer CSV file available at superdatascience.com (https://www.superdatascience.com/pages/powerbi), I developed two schemas to drive home the knowledge. The file consists of a table that has the following columns: CustomerID, Name, Surname, Gender, Age, Region, Job Classification, Date Joined, and Balance.
I developed a star schema by creating five (5) dimension tables using the sample data columns and a fact table that holds foreign keys from all five (5) dimension tables and a unique key per transaction as shown below:
Table 1: A table that holds five (5) dimension tables created for the star schema for UK Bank Customer data warehouse
| S/N | Dimension Table | Column(s) |
| 1 | Date Table | Date Joined |
| 2 | Customer Table | Customer ID, Name, Surname & Age |
| 3 | Gender Table | Gender |
| 4 | Job Classification Table | Job Classification |
| 5 | Region Table | Region |
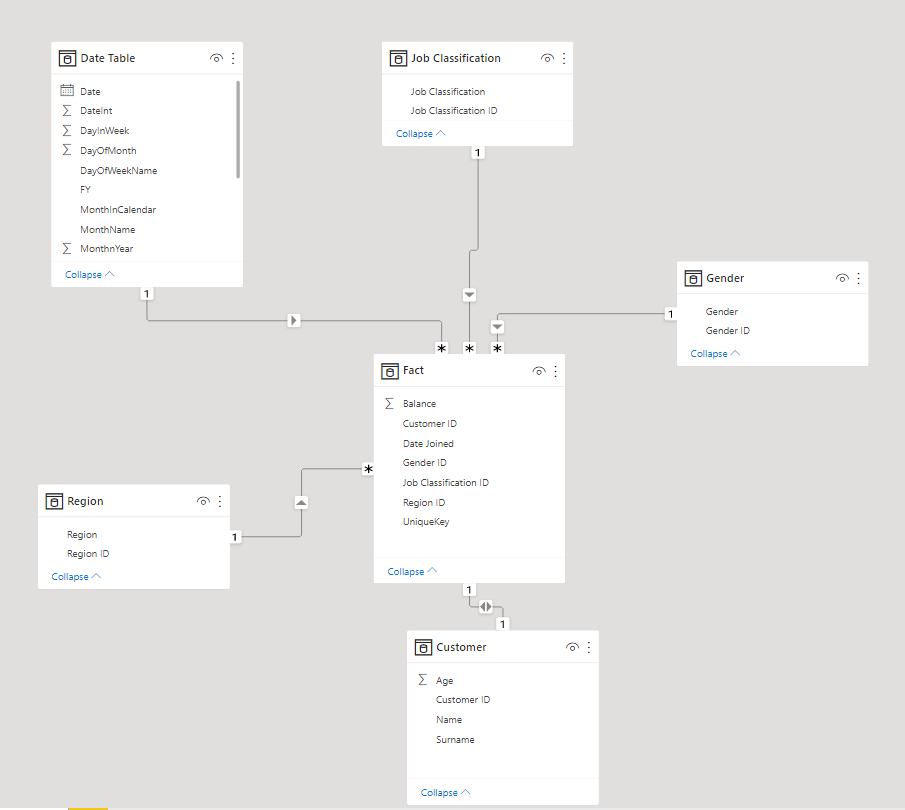
Figure 2: A Star Schema for UK Bank Customer data warehouse.
In a bid to develop a snowflake schema, I developed two sub-dimension tables (city, job type) to support our work in the second scenario. The city table is connected to the region table while the job type is linked to the job classification as shown in the figure below:
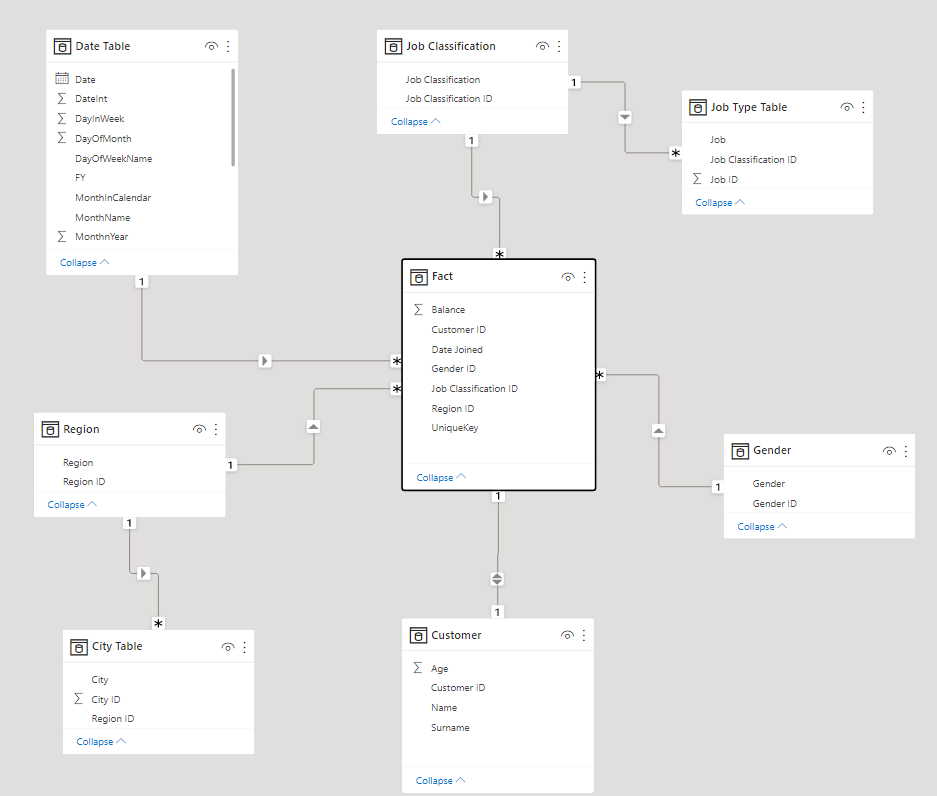
Figure 3: A Snowflake Schema for UK Bank Customer data warehouse.
Here is a comparative analysis between the star and snowflake schemas.
| S/N | Parameter | Star Schema | Snowflake Schema |
| 1 | Performance | The execution speed in the set-up is quite faster than the other since there is a direct connection between the fact table and the dimension tables hence the performance is better | The introduction of the sub-dimension tables usually impacts the DW performance greatly due to the increased number of joins performed in this setup |
| 2 | Design | Design a star-schema data warehouse is simple and straight forward especially when one considered the limited use of data merging techniques (join and append) | You need an experienced data architect to design and develop a snowflake DW for a large dataset. There is a need to optimize the use of data merging techniques so one can avoid circular references. |
| 3 | Flexibility | While the design is simpler than snowflake schema, it is quite rigid especially when there is a need to scale the data structures | With a proper knowledge of joins, this data representation can be modified with a need to drop/delete existing tables. |
| 4 | Query Complexity | A simple query can easier fetch data from the different tables in set-up. | With a higher number of tables in the configuration, there is a need to develop complex query using techniques like sub-query to fetch data. |
| 5 | Hardware Resource | In a star data layout, the dimension tables are usually large and contain redundant data. This usually demand much space and memory on the hardware resources. | Normalized tables in the tables in this configuration doesn’t requires much space and memory on the hardware resources |
Conclusion
In this blog, we discussed what a data warehouse is and the two most used approaches used to develop a data warehouse: Star Schema and Snowflake Schema. We can see that both schemas have their significant importance and can be implemented in any application depending on the cost resource, data volume and other constraints.
{kind=link}